Temos 3 casos possíveis ao executar um algoritmo: melhor caso, pior caso e caso médio ou esperado.
O melhor caso é a execução com o menor número possível de instruções (ou seja, a mais eficiente).
O pior caso é a execução com o maior número possível de instruções (menos eficiente). Fornece um 'teto' para o número de instruções.
O caso médio é a média ponderada de todas as entradas e suas chances de ocorrer.
Os casos são causados por comandos condicionais, porque estes direcionam a caminhos diferentes de execução e esses caminhos podem ter mais ou menos comandos. Alguns exemplos pra entender direitinho:
Busca pelo maior elemento (entrada:vetor; saída: índice do maior elemento):
- num vetor de n elementos, são executadas n-1 comparações. Afinal, nunca saberemos se um número é o maior se não testarmos todos.
- num vetor de n elementos, podem ser executadas entre 1 e n atribuições (do índice do maior elemento pra variável que for retornar). Considerando o nº de atribuições:
- melhor caso: o elemento está na primeira posição
- pior caso: o elemento está na última posição
- caso médio: o elemento está no meio
Busca pelo maior E menor elementos (entrada:vetor; saída: índices do maior e menor elementos):
- utilizando o seguinte método:
if (a[i] > max) max = i;
if (a[i] < min) min = i;
- num vetor de n elementos, são executadas 2n-2 comparações. Afinal, nunca saberemos se um número é o maior ou menor se não testarmos todos.
- utilizando o seguinte método, que faz muito mais sentido porque se um elemento é maior, ele não pode ser o menor, nem precisa conferir:if (a[i] > max) max = i;else if (a[i] < min) min = i;
- melhor caso: n-1 comparações com o maior elemento na primeira posição
- pior caso: 2n-2 comparações com o maior elemento na última
- caso médio: supondo 50% de chance de o elemento ser maior que o anterior e não entrar no else e 50% de chance dele não ser maior que o anterior e entrar, temos o seguinte: f(n) = ((n-1) + (2n-2)) / 2 = 3/2 (n-1) comparações em média
Algoritmo de busca sequencial de um elemento no vetor:
- o elemento pode existir ou não, e a análise de complexidade é feita separadamente para essas duas hipóteses.
- a busca é sequencial, ou seja, vai procurando no vetor até achar ou chegar no fim, indicando que não achou o elemento procurado.
- pesquisa sem sucesso: são feitas n comparações para constatar que o elemento não esta lá.
- pesquisa com sucesso:
- melhor caso: o elemento está na primeira posição (1 comparação)
- pior caso: o elemento está na última (n comparações)
- caso médio: média ponderada dos casos e suas probabilidades. Como não sabemos probabilidades específicas, podemos considerar todas iguais (p = 1/n). Assim, temos f(n) = 1/n (1 + 2 + 3 + ... + n), resultando em (n+1)/2

 , onde:
, onde: dividindo a equação por a1(x)
dividindo a equação por a1(x) , implicando que
, implicando que 
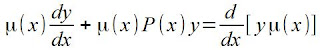



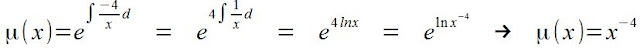



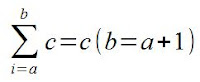





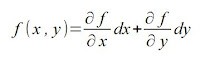
 . Teremos também
. Teremos também  , logo
, logo  porque as derivadas parciais mistas são iguais.
porque as derivadas parciais mistas são iguais.