Ordenar é arranjar um conjunto de elementos de acordo com determinada relação. É muito importante para pesquisar e apresentar dados e informação.
Alguns conceitos a serem conhecidos:
Arquivo: é um conjunto de n itens para ser ordenado;
cada Item é um objeto ou registro;
cada Registro contém uma Chave k que governa o processo de ordenação;
podem existir chaves iguais;
Os métodos de ordenação podem ser divididos assim:
Classificação de algoritmos quanto ao método de ordenação:
A ordenação por comparação é quando se observa duas chaves como valores e as compara. É adequada para qualquer tipo de dados e não tem restrições quanto às chaves. Existem quatro tipos de ordenação por comparação:
1) Ordenação por inserção: os itens são considerados um a um e cada novo item é inserido na posição correta relativa aos itens previamente ordenados
2) Ordenação por troca: se dois itens estão fora de ordem, eles são trocados; o processo é repetido até que não sejam necessárias mais trocas
3) Ordenação por seleção: o menor elemento é escolhido e separado dos demais; o processo se repete para os elementos restantes até que reste apenas um elemento
4) Ordenação por enumeração: cada item é comparado com todos os demais; a contagem do número de chaves menores determina a posição relativa do item no conjunto; método exige espaço adicional: não tem interesse prático
A ordenação digital observa os dígitos das chaves separadamente. É mais aconselhada para chaves com um mesmo número de dígitos, ou que seguem uma distribuição uniforme.
Classificação de algoritmos quanto ao espaço requerido pelos métodos:
A ordenação interna é aquela na qual a quantidade de dados cabe na memória principal. O acesso aos dados é mais fácil e pode ser aleatório, permitindo maior flexibilidade na estruturação dos dados.
As operações relevantes para algoritmos internos de comparação são o número de comparações entre chaves, o número de trocas dos elementos e o número de movimentações. O custo varia de acordo com o tamanho do arquivo e o arranjo inicial dos dados. São classificados em
- algoritmos simples (complexidade quadrática): são melhores pra arquivos pequenos. Alguns exemplos são o bubble, insertion, selection e enumeração.
- algoritmos eficientes (complexidade n logn ou n^(3/2)): são mais sofisticados e recomendados para arquivos grandes. Tipo quicksort, shellsort, heapsort, etc.
A ordenação externa é a que os dados não cabem na memória principal, requirindo uso de memória secundária. Há restrições para o acesso dos dados, tornando o acesso sequencial mais rápido do que o aleatório.
Classificação de algoritmos quanto à estabilidade:
Algoritmo estável é aquele que preserva a ordem relativa dos dados. Por exemplo, se pegamos uma lista de clientes de banco e ordenamos primeiro alfabeticamente depois por saldo, os clientes com mesmo saldo permanecem em ordem alfabética - são feitas duas ordenações com chaves diferentes.
A ordenação instável não mantém essa ordem relativa dos dados.





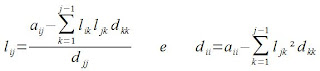 .
.
 .
. . Caso o campo seja uniforme, ele se reduz a
. Caso o campo seja uniforme, ele se reduz a  , em que s é a direção perpendicular às superfícies equipotenciais. A componente paralela às superfícies é 0.
, em que s é a direção perpendicular às superfícies equipotenciais. A componente paralela às superfícies é 0.